

Free Download!
Free Download!
Crime and Place™ focuses on presenting well established, long term trends in criminal activity in the United States. We believe this paints a more accurate picture of overall crime levels in a given area, when compared to individual crime incidents.
The application uses aggregated personal and property crime data based on an extensive analysis of several years of FBI Uniform Crime Report statistics combined with numerous characteristics taken from the US Census and other sources. Considerable effort was made to standardize data, and manually correct inconsistencies, discrepancies and errors.
Each of the seven crime types were modeled separately, and separate models were constructed for the nine Census regions to account for regional differences in crime rates and the characteristics that underlay them. The results of these models were then applied to the Census block group level using the same characteristics, weighted by population, and aggregated to national totals.
Individual estimates were converted to indexes relative to national totals and rescaled, with the end result being a raw metric for each crime type, for every Census block group in the United States.
5 year Crime Forecasts are calculated similarly. Like with the current year data, crime rates are based on FBI Uniform Crime Report statistics combined with US Census characteristics, but these data are based on 5-year projected demographic data. These estimates are scaled, balanced and normalized similar to the current year data before being converted to indexes relative to the projected national averages.
When looking at the raw crime metrics, we found the distributions to be very asymmetrical, skewed highly towards lower crime rates, with a very large range. The image below shows the distribution of raw data for the murder crime metric (the normal curve appears in orange).
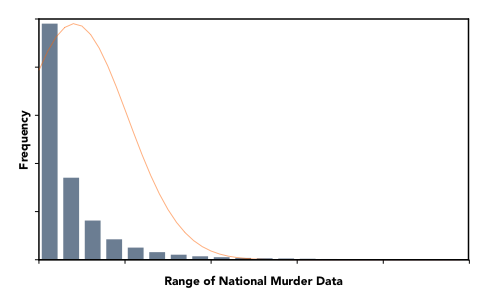
It is difficult to visualize and interpret this type of distribution. For example, there could appear to be very low variability of crime in a particular location, when that is actually not the case.
To convert raw metrics to the crime scores displayed throughout the application, we first had to transform the data to a scale that better honored and stabilized the variability of the data. This was done in part, by using a log-transformation. The validity of this approach can be confirmed by observing that the raw data is log-normally distributed – i.e. a log-transformation results in a normal distribution.
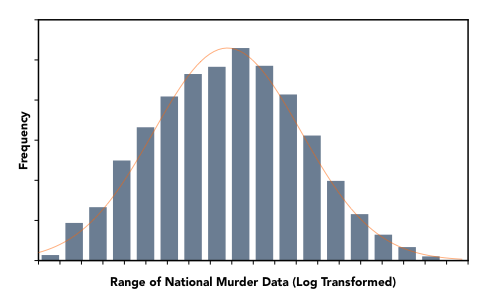
For a given location and crime type, individual metrics are scored on a base-2 logarithmic scale from 1 to 10, with scores being relative to the national average for that metric. Similar to the Richter scale, increases or decreases are multiplicative, not linear. In this case, a 1-point increase equates to a doubling of crime.
The scale is shifted such that the lower and upper bounds make sense for the range of available data. Major thresholds on the scale are defined as follows:
| Score | Meaning |
|---|---|
| 1 | 1/8 x NA (National Average) |
| 2 | 1/4 x NA |
| 3 | 1/2 x NA |
| 4 | 1 x NA |
| 5 | 2 x NA |
| 6 | 4 x NA |
| 7 | 8 x NA |
| 8 | 16 x NA |
| 9* | 32 x NA |
There are two categories of crime displayed in the application – personal crime and property crime.
Personal crime consists of the following crime types:
Property crime consists of:
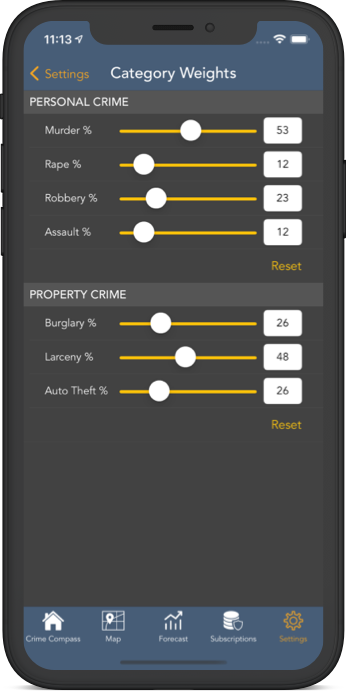
Once crime scores are calculated for each crime type, the scores are aggregated based on customizable weightings to produce an overall score for each category. By default, each crime type received equal weighting, however crime category weights can be modified from within the application's settings, and crime scores will dynamically update accordingly.
As mentioned earlier, crime data applies to a US Census block group, which are statistical divisions of census tracts made up of one or more census blocks. Although these divisions are necessary when reporting crime statistics and demographics, their borders are somewhat artificial in practice.
Rather than adhere strictly to the census divisions, we use a hybrid (yet dynamic) nearest-neighbor and Voronoi gridding algorithm, which compares a user's location to the nearest center of population within a block group, and interpolates data accordingly (with the assumption that within a given area, the majority of crime will take place at the center of population, rather than the geographic center). As a result, the application has full data coverage for all US locations.
All calculations and mapping take place in real-time.